- Home ›
- Perlにおける正規表現 ›
- 任意の文字と繰り返し(量指定子) ›
- HERE
任意の文字を繰り返し
任意の一文字にマッチするメタ文字(.)とメタ文字(*)やメタ文字(+)を組み合わせることで、任意の文字が繰り返し現れた場合にマッチする正規表現を作成することが出来ます。
例として「a」と「b」の間に任意の文字が繰り返し現れるパターンは次のようになります。
/a.+b/
上記の場合、メタ文字(+)の直前の文字がメタ文字(.)となっています。「+」は直前の文字を1回以上繰り返す場合にマッチし、「.」は任意の一文字にマッチします。結果として「.+」は任意の文字が1回以上繰り返す場合にマッチすることになります。よって「a」と「b」の間にどんな文字が何文字記述されていてもマッチすることになります。
マッチするもの:
aPb abowb a1098opeb
また詳しくは次のページで解説しますがデフォルトでは最大限にマッチする範囲が多くなる位置でマッチします。
a0000b1111b2222b
対象が上記のような文字列だった場合にパターン「/a.+b/」は「a0000b」にも「a0000b1111b」にも「a0000b1111b2222b」にもマッチします。このような場合はマッチする範囲が最大にある「a0000b1111b2222b」にマッチします。
改行も含めて任意の文字を繰り返す
任意の一文字を表すメタ文字(.)は改行にはマッチしません。そこで改行も含めて任意の文字を繰り返す場合には別の記述方法を使います。
例として「a」と「b」の間に改行も含めた任意の文字が繰り返し現れるパターンは次のようになります。
/a[¥d¥D]+b/
この場合、文字クラスを表すブラケット[]の中に数字を表す「¥d」と数字以外を表す「¥D」を記述しています。文字クラスは[]に列挙された文字のいずれかにマッチしますので、数字か数字以外のいずれかにマッチすることになりますので結果として全ての文字にマッチすることになります。(文字クラスについては「いずれかの文字に一致(文字クラス)」を参照して下さい)。
同じように「/[¥w¥W]+/」や「/[¥s¥S]+/」でも同じです。また「/s修飾子」を使用しても可能ですが、こちらはまた修飾子の箇所で解説します。
サンプルプログラム
では簡単なプログラムで確認して見ます。
use strict;
use warnings;
use utf8;
binmode STDIN, ':encoding(cp932)';
binmode STDOUT, ':encoding(cp932)';
binmode STDERR, ':encoding(cp932)';
print "「P.+P」にマッチするかどうか¥n";
print "(マッチする場合は括弧の中にマッチした部分を表示)¥n¥n";
&check1("aPooPa");
&check1("aPoPoPa");
&check1("aPoo¥nPmmmPa");
print "¥n「P[¥¥d¥¥D]+P」にマッチするかどうか¥n";
&check2("aPoo¥nPmmmPa");
sub check1{
my ($str) = @_;
if ($str =~ /P.+P/){
print "○:$str ($&)¥n";
}else{
print "×:$str¥n";
}
}
sub check2{
my ($str) = @_;
if ($str =~ /P[¥d¥D]+P/){
print "○:$str ($&)¥n";
}else{
print "×:$str¥n";
}
}
上記を「test7-1.pl」の名前で保存します(文字コードはUTF-8です)。そしてコマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
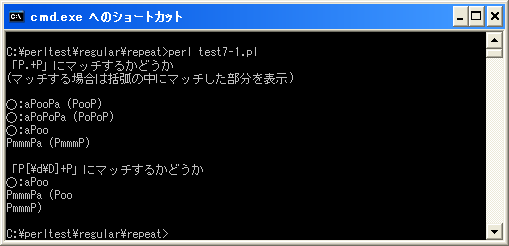
今回の場合、マッチした場合にはどの部分にマッチしたのかを合わせて表示するようにしています。「aPoo¥nPmmmPa」に対し、パターン「/P.+P/」は「Poo¥nP」にはマッチしないため「PmmmP」にマッチします。それに対して「P[¥d¥D]+P」は改行も含めてマッチするため「Poo¥nPmmmP」にマッチします。
( Written by Tatsuo Ikura )
