- Home ›
- Perlにおける正規表現 ›
- 任意の文字と繰り返し(量指定子) ›
- HERE
グループ化して複数の文字を対象にする
メタ文字の「*」「+」「?」及び範囲を指定する{min,max}を使用する場合、対象は直前の一文字でした。ここでは一文字ではなく複数の文字を1つのグループとして扱い、複数の文字を繰り返しの対象にする方法を確認します。
複数の文字を対象にするには、複数の文字を()で囲みグループにします。記述方法は次のようになります。
(複数の文字)*
例えば「good!」と言う4つの文字が1回以上繰り返されて現れた場合にマッチする正規表現は次の通りです。
/(good!)+/
上記の場合、「(」から「)」で囲まれた間に書かれた文字が1つのグループとなります。そしてメタ文字の「+」は直前にある文字が1回以上繰り返された場合にマッチしますが、今回は直前の文字がグループなのでグループの中の複数の文字が1回以上繰り返された場合にマッチします。
マッチするもの:
good! good!good! good!good!good!good!good!
このように()で囲まれた複数の文字を1つの単語のように扱い、単語が繰り返しの対象となります。
今回はグループにすることで繰り返しの対象を一つの文字以外にも適用するようにしましたが、繰り返しを表すメタ文字はその直前にあるものが対象となり一つの文字だけが対象とならない場合もあります。具体的には他のページで順次解説していきます。
サンプルプログラム
では簡単なプログラムで確認して見ます。
use strict;
use warnings;
use utf8;
binmode STDIN, ':encoding(cp932)';
binmode STDOUT, ':encoding(cp932)';
binmode STDERR, ':encoding(cp932)';
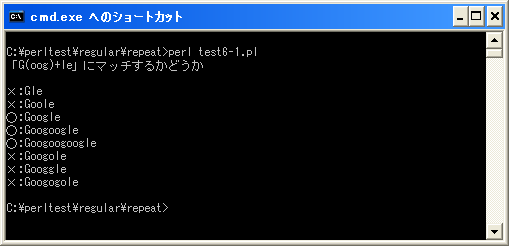
print "「G(oog)+le」にマッチするかどうか¥n¥n";
&check("Gle");
&check("Goole");
&check("Google");
&check("Googoogle");
&check("Googoogoogle");
&check("Googole");
&check("Googgle");
&check("Googogole");
sub check{
my ($str) = @_;
if ($str =~ /G(oog)+le/){
print "○:$str¥n";
}else{
print "×:$str¥n";
}
}
上記を「test6-1.pl」の名前で保存します(文字コードはUTF-8です)。そしてコマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
( Written by Tatsuo Ikura )
