- Home ›
- Perlにおける正規表現 ›
- マッチした部分の取得 ›
- HERE
マッチした文字列の前後を取得($`, $')
広告
前のページにてパターンにマッチした部分を取得しましたが、マッチが成功した時にマッチした部分よりも前の部分と後の部分をそれぞれ取得することが可能です。
$` マッチした部分よりも前の部分が格納される $' マッチした部分よりも後の部分が格納される
具体的な例で考えてみます。
my $str = "book is 2000yen, cake is 800yen";
if ($str =~ /¥d+yen/){
print "マッチした文字列 : $&¥n";
}
マッチが成功した場合、自動的に変数「$&」にはマッチした文字列全体が格納されます。今回の場合は「2000yen」です。そして同じように特別な変数「$`」にはマッチした文字列より前の部分「book is 」が格納され、また特別な変数「$'」にはマッチした部分より後の部分「, cake is 800yen」が格納されます。
変数「$`」と変数「$'」は次に書き換えられるまでマッチした文字列が格納されていますので、変数の値を表示したり他の変数に値を格納したりすることが出来ます。
my $str = "book is 2000yen, cake is 800yen";
if ($str =~ /¥d+yen/){
print "前の部分 : $`¥n";
print "マッチした文字列 : $&¥n";
print "後の部分 : $'¥n";
}
なお「$&」同様「$`」と「$'」も処理効率が悪いと言われています。
サンプルプログラム
では簡単なプログラムで確認して見ます。
use strict;
use warnings;
use utf8;
binmode STDIN, ':encoding(cp932)';
binmode STDOUT, ':encoding(cp932)';
binmode STDERR, ':encoding(cp932)';
&check("book is 2000yen, cake is 800yen");
&check("orange is 950yen");
&check("3500yen?");
sub check{
my ($str) = @_;
if ($str =~ /¥d+yen/){
print "<$`><$&><$'>¥n";
}
}
上記を「test2-1.pl」の名前で保存します(文字コードはUTF-8です)。そしてコマンドプロンプトを起動し、プログラムを保存したディレクトリに移動してから次のように実行して下さい。
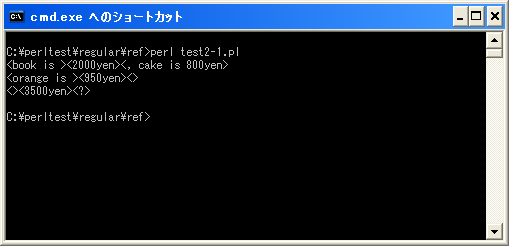
今回のサンプルでは、マッチした部分、そしてその前後をそれぞれ「<」と「>」で囲んで表示しています。
( Written by Tatsuo Ikura )
